It is amazing how easily you can do text recognition with Python. Pytesseract is an amazing library that acts as a wrapper for Google's Tesseract-OCR. You can literally do text recognition on images with few lines of code. I made a simple script that does exactly that. Tesseract can also detect Bengali Language which makes it more useful to me. Here's my repository just in case you'd want to know how I built it.
Bust basically what I did was import few libraries such as glob(to iterate through folders), Pillow(to read images) and Pytesseract. Then I iterated through folders and put images files ending with ".jpg" in a function that reads the image and uses Pytesseract's image_to_string method and passed the image and it returns the text form of it. Here's the script in action:
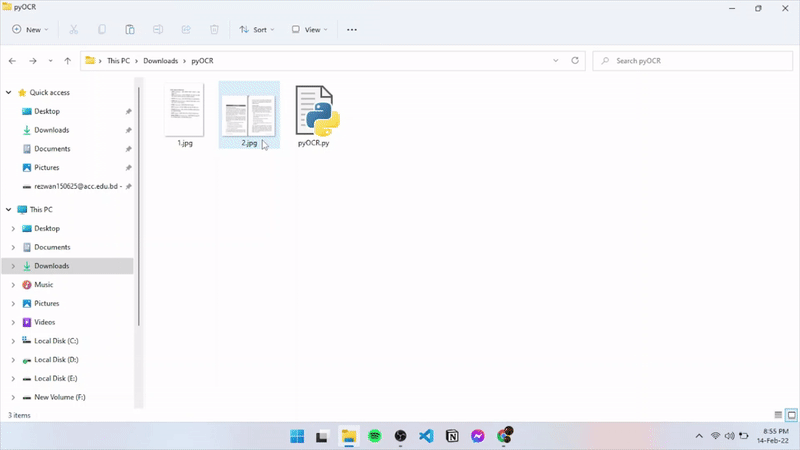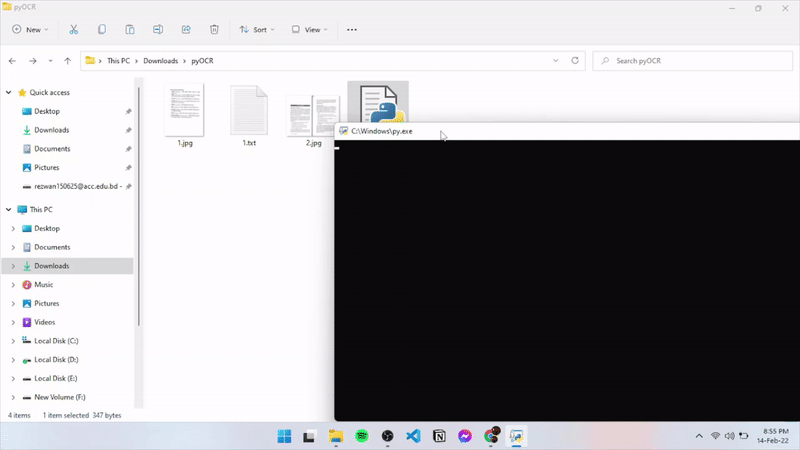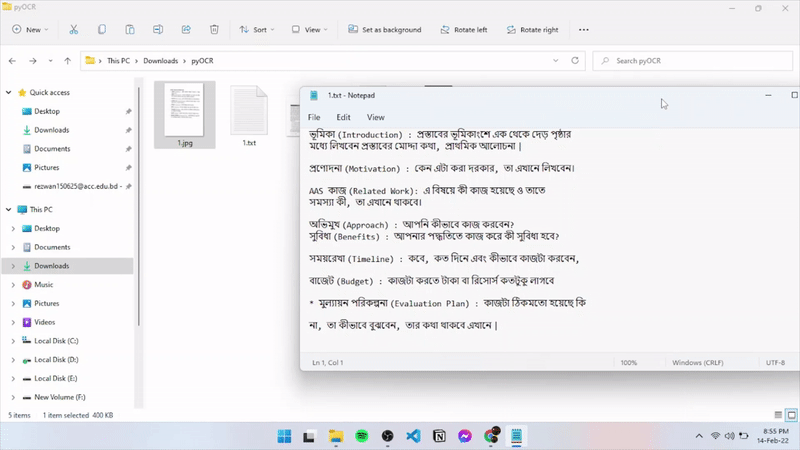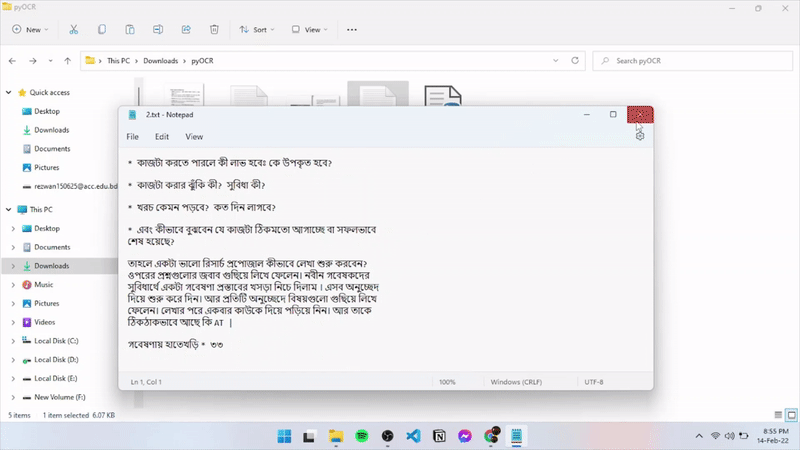
And here's the script:
from PIL import Image
import pytesseract
import glob
def ocr(file_to_ocr):
image = Image.open(file_to_ocr)
txt = pytesseract.image_to_string(image, lang="ben+eng")
return txt
for file in glob.glob("*.jpg"):
txt = ocr(file)
with open(f"{file[:-4]}.txt", "w", encoding="utf-8") as f:
f.write(str(txt))
Setting Up
Now the program won't work if you don't setup your desktop environment correctly. Here's how you should setup your environment:
1. First download the latest version of tesseract-ocr-setup-3.xx.xx.exe from here.
2. Install it like you normally install a software
3. Install Python from the official website and make sure you click on "Add to Path" option while installing.
4. After it's done open the command prompt and type pip install Pillow pytesseract
And you should be good to go. You're done setting up. Just put the script in the folder where you have the images that needs to be OCR'd and just double click on the script.